Récupérer les métadonnées des PDF🔗
Informations sur la page
Consulter cette page dans la documentation officielle de Zotero : Retrieve PDF Metadata - dernière mise à jour de la traduction : 2022-09-02
Les nouveaux utilisateurs de Zotero peuvent trouver la perspective d'importer toutes leurs données quelque peu décourageante. De nombreux chercheurs disposent déjà d'une importante collection de fichiers PDF qu'ils ont précédemment organisés manuellement ou à l'aide d'un autre logiciel. Zotero permet d'importer facilement ces PDF et de récupérer les métadonnées bibliographiques complètes (pour la recherche, la citation, l'indexation et l'organisation), allégeant ainsi considérablement le travail de migration.
Pour utiliser cette fonctionnalité, faites simplement glisser vos PDF dans votre bibliothèque Zotero ou utilisez les options "Stocker une copie du fichier..." ou "Lien vers un fichier..." dans le menu "Nouveau document" ( ). Par défaut, Zotero va récupérer automatiquement les métadonnées des PDF et renommer les fichiers associés. Si vous préférez, vous pouvez désactiver ces fonctions automatiques dans l'onglet "Générales" des préférences de Zotero.
). Par défaut, Zotero va récupérer automatiquement les métadonnées des PDF et renommer les fichiers associés. Si vous préférez, vous pouvez désactiver ces fonctions automatiques dans l'onglet "Générales" des préférences de Zotero.
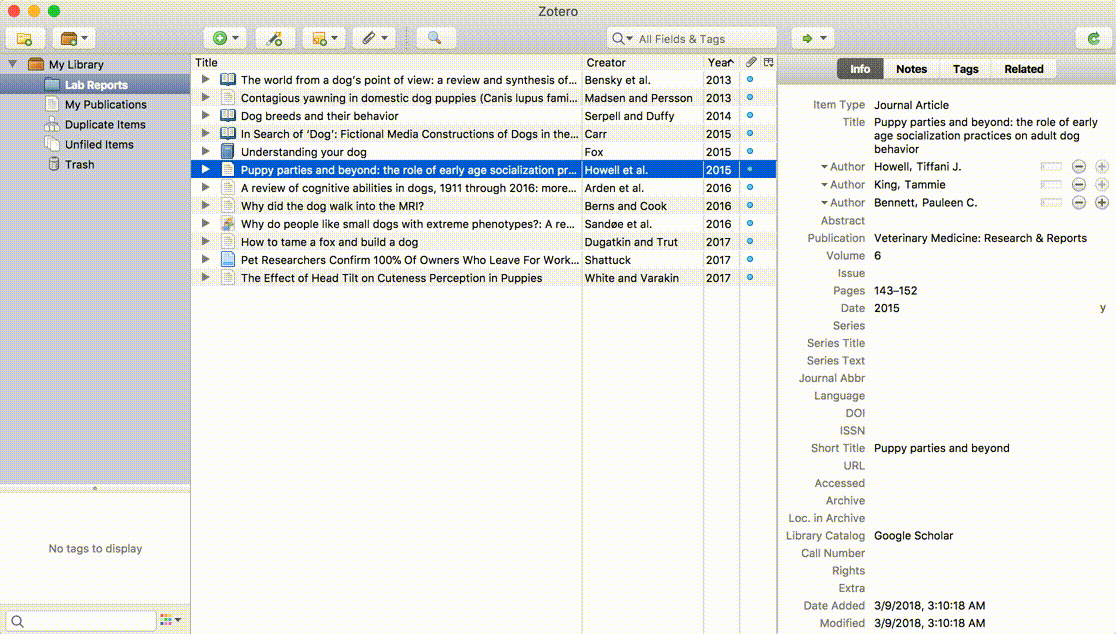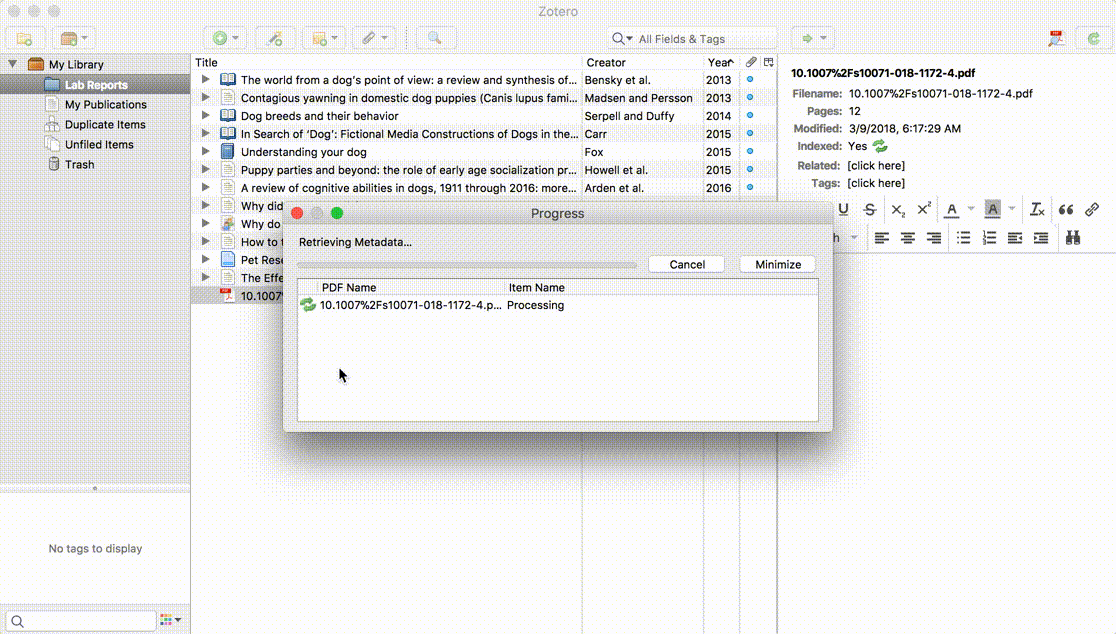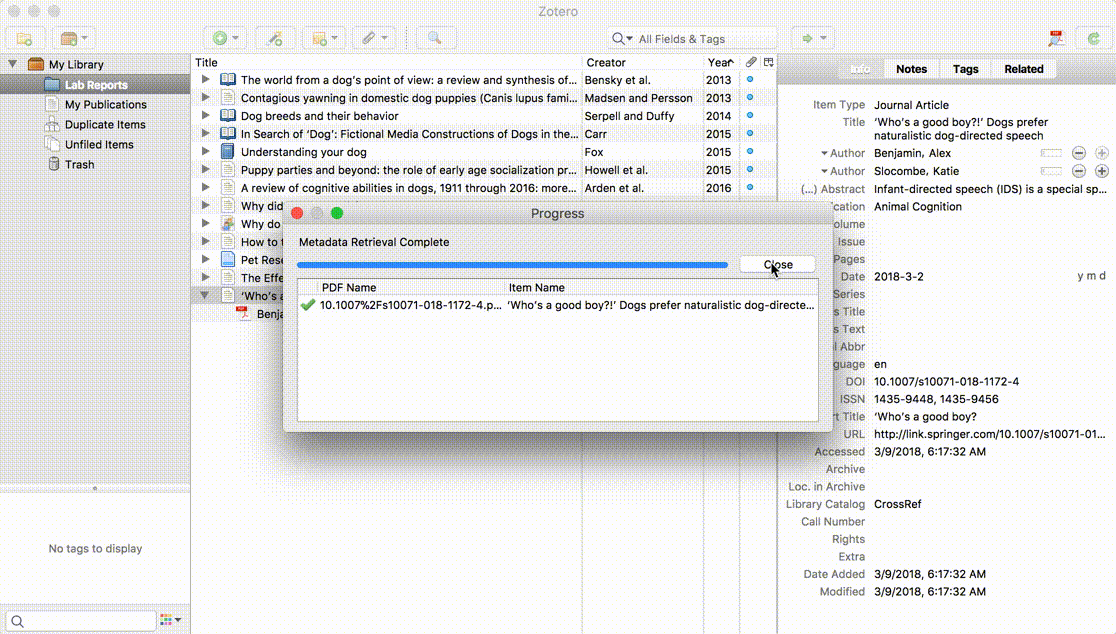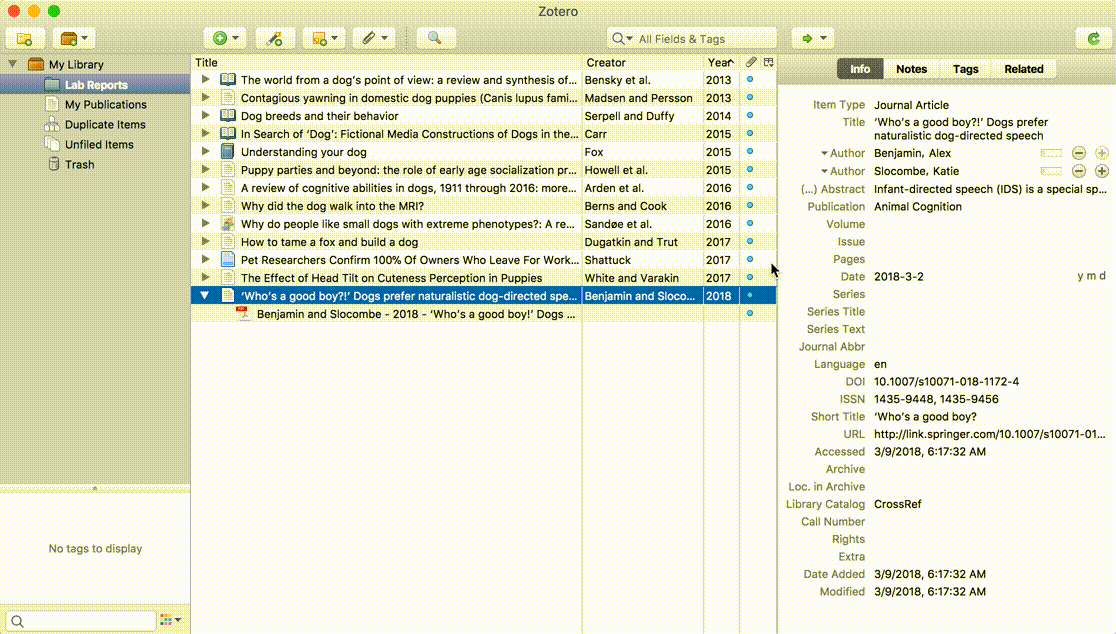
Si Zotero trouve les informations correspondant au PDF, il va créer un document Zotero complet avec les données disponibles, et y joindre le PDF. S'il n'y parvient pas, il laissera le PDF comme pièce jointe indépendante. Vous pouvez alors ajouter le document parent d'une autre manière − soit en enregistrant un document depuis le web et en glissant ensuite le PDF sur ce nouveau document, soit en fasant un clic droit sur le PDF, en choisissant "Créer un document parent", et enfin en indiquant un identifiant tel qu'un DOI ou un ISBN. Si ces procédures ne fonctionnent pas, vous pouvez aussi cliquer sur "Saisie manuelle" après avoir sélectionné "Créer un document parent", et compléter manuellement les métadonnées pour le document.
Si vous n'êtes pas satisfait des métadonnées récupérées automatiquement, vous pouvez faire un clic droit sur le nouveau document parent et sélectionner "Annuler la récupération des métadonnées" pour laisser le PDF comme pièce jointe indépendante, afin de le traiter par d'autres opérations manuelles.
Zotero devrait parvenir à récupérer des métadonnées de bonne qualité pour la plupart des PDF académiques. Il peut parfois parvenir à extraire des métadonnées simples (titre, auteur) pour d'autres documents, mais vous ne devriez pas vous attendre à ce que cela fonctionne − tout peut être diffusé sous forme de PDF, mais cela ne veut pas dire qu'il existe des métadonnées standard pour tout document.
Note: Bien que cette fonctionnalité puisse considérablement faciliter l'importation de grandes bibliothèques existantes de fichiers PDF, ce n'est pas, en général, la meilleure façon d'ajouter des documents à votre bibliothèque. Les documents peuvent être importés plus rapidement à partir des sites Web des éditeurs ou de la plupart des bases de données bibliographiques, en utilisant le connecteur Zotero de votre navigateur. Cela permet d'économiser plusieurs étapes par rapport au téléchargement manuel du PDF et à son ajout dans Zotero. Les métadonnées des documents seront aussi souvent de meilleure qualité. Voir Ajouter des documents à Zotero pour les meilleurs moyens d'ajouter des documents à votre bibliothèque.
Comment cela fonctionne🔗
La fonction "Récupérer les métadonnées du PDF" utilise un service Web de Zotero pour trouver les métadonnées du document. Le client Zotero envoie les premières pages du PDF au service Web, qui utilise des algorithmes d'extraction et des métadonnées connues de CrossRef, associés à des recherches DOI et ISBN, pour créer un document parent pour le PDF. Ce service de recherche de Zotero ne nécessite pas de compte Zotero et n'enregistre aucune donnée sur le contenu ou les résultats des recherches.